In Biology, What Is a Consensus Sequence?
A consensus sequence is a set of proteins, or nucleotides in deoxyribonucleic acid (DNA), that appears regularly. DNA is composed of nucleotides and each nucleotide is composed of a phosphate, a sugar and a nitrogen base. Nitrogen bases can be adenine (A), thymine (T), guanine (G) and cytosine (C). The sequence of these chemical bases determine the genetic code of an organism. The genetic code is like an instruction upon which an organism is built and maintained. Molecular biologists often use statistics to predict the location of sequences, or to understand where particular molecules tend to bind. Formulas can be used to represent locations where amino acid sequences remain the same and locations where they vary. In the case of a consensus promoter sequence,for example, a particular type of enzyme can bind to sites of similarly sequenced proteins.
Geneticists, like researchers in many scientific disciplines, often use substitutions to simplify complex systems. There are so many amino acid bases and genes in the body that scientists cannot count them unless there is some general system for doing so. A consensus sequence can appear in many locations in DNA as well in various living things. The similarities and differences that tend to occur can be indicated by a formula.
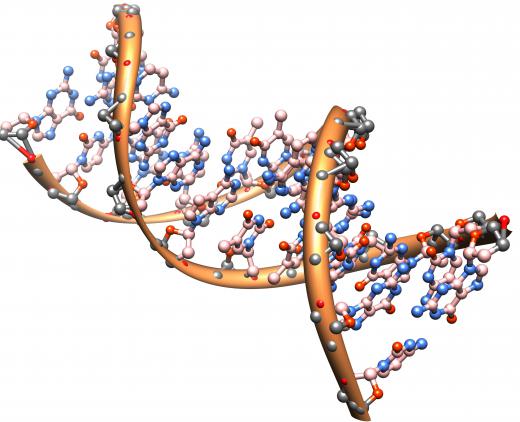
Statistically, scientists can classify genetic sequences to look for patterns. Repeating patterns, called sequence motifs, are generally used to represent genetic areas that control specific biological processes. Consensus sequences can also offer insight into how proteins are synthesized or how molecules are guided within a cell.
In the notation of a consensus sequence, the location of some nucleotides can show that they are always in the represented location. It can also be indicated that one nucleotide or another can be there. In this case, how frequently an amino acid appears, in place of another, is generally not stated. A graphical model is sometimes used to indicate this frequency, by increasing or decreasing the size of symbols. Some software programs can generate sequence logos automatically.

Often, a consensus sequence matches up with a recognized protein binding site. To accurately depict sequences on the genome, mathematical formulas are often used. These include statistical formulas such as logarithms and numerical values, which can be positive or negative, to represent the location of genetic information. Processes in the genome for normal biological functions, as well as those related to diseases, can be analyzed in this way.
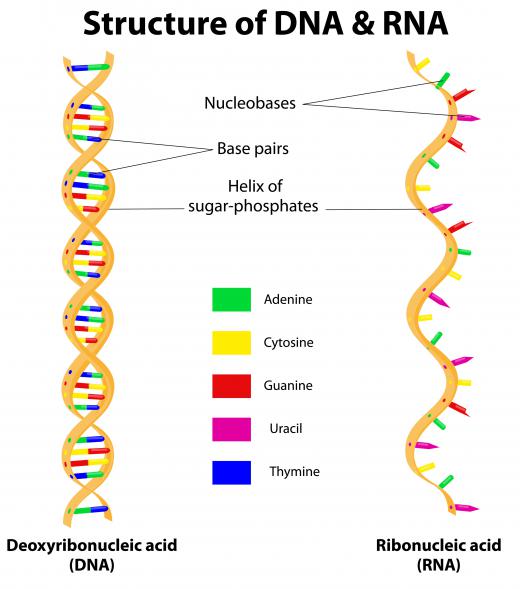
The mathematical representations of a consensus sequence generally provide a model of DNA and amino acid patterns. An exact picture is typically not provided. The sequences, however, can help scientists relate the functional aspects of different parts of the genome to evolutionary patterns of organisms.
AS FEATURED ON:
AS FEATURED ON:

-
![DNA might contain several appearances of a consensus sequence.]() By: ermessDNA might contain several appearances of a consensus sequence.
By: ermessDNA might contain several appearances of a consensus sequence. -
![Consensus sequences can offer insight into how proteins are synthesized.]() By: nandyphotosConsensus sequences can offer insight into how proteins are synthesized.
By: nandyphotosConsensus sequences can offer insight into how proteins are synthesized. -
![A consensus sequence is a set of proteins in DNA that appears regularly.]() By: designuaA consensus sequence is a set of proteins in DNA that appears regularly.
By: designuaA consensus sequence is a set of proteins in DNA that appears regularly.



Discuss this Article
Post your comments